
Day9-10. 미니 프로젝트 1차
- 주제: 서울시 생활 정보 기반 대중교통 수요 분석
- 데이터 분석과 인사이트 도출
첫 번째 미니 프로젝트를 월 ~ 수 3일 동안 진행됐다. 아직 실력이 너무 부족한 것 같은데 벌써 프로젝트라고? 하는 마음과 다른 에이블러분들을 처음 뵙기에 떨리고 긴장도 됐다 ㅎㅎ 지금까지 여러 미니프로젝트를 해보며 느낀 점은 중간중간 미니 프로젝트로도 정말 많이 배운다는 것이다. 수업 들을 때 마냥 따라 해 보고 이해에 집중하고 있던 내용들을 직접 생각해서 코드를 짜고 적용하는 과정에서 부족했던 부분을 찾고 많이 배우고 있다. 무엇보다 전체 발표 시간에 다른 조의 발표를 보면서도 몰랐던 내용들을 아주 많이 배우고 있다.
첫 번째 미니 프로젝트 이틀 동안은(월, 화) '서울시 생활정보 데이터(인구, 상권)로 대중교통(버스) 수요 분석'을 진행했다. 서울시와 KT는 시민들의 통신 데이터 등 여러 빅데이터를 통해 올빼미 버스라고 불리는 심야버스 노선 선정 성공 사례가 있다. 이처럼 이번 프로젝트의 주제는 서울 유동인구와 같은 인구 정보와 버스 승하차 인원 및 운행 노선 분석을 통해 버스 시설 추가가 필요한 대상 지역을 선정하는 것이었다.
✅ 도메인 지식
데이터 분석을 통해 문제 해결을 위한 솔루션을 도출하기 위해선 해당 데이터 분야의 도메인 지식에 대한 충분한 이해가 필요하다. 이번 주제에 대해선 교통 분야, 서울시 관련, 버스 노선 관련 도메인 이해가 필요하다. 예를 들어, 서울시에는 현재 25개 구가 있으며 인구가 가장 많은 구는 송파구, 가장 적은 구는 중구이다. 서울의 버스 노선 수는 약 375개 정도이다.
✅ 데이터셋
프로젝트에 사용한 데이터는 총 4개(서울 버스 승하차 이용 데이터, 서울 구별 유동 인구 데이터, 서울 구별 주민 등록 인구 데이터, 서울 구별 업종 등록 데이터)이다. EDA를 활용하여 해당 데이터를 살펴보고 가설을 세워 검증하는 과정을 가졌다.
✅ 과정
우리 조는 대면 가능하신 분들은 3일 모두 만나서 진행했다. 다만 월요일은 실습자료와 제공받은 데이터를 바탕으로 조원 미팅 전까지 데이터 전처리 과정과 가설 수립과정이 개별로 진행됐다. 완전 처음부터 데이터 전처리를 해나가는 과정은 또 낯설었기에 월요일엔 전처리만 하는 데에도 시간이 꽤 소요됐다. 화요일은 함께 각자의 가설 수립 및 검증 과정을 공유하고 공통의 가설을 선정해서 추가로 검증과정을 거쳤다. 가설 선정 과정에선 Mural이라는 툴을 추천받아서 사용했다. 이후 발표 PPT를 제작했다.
<개별 실습 과정>
정류장 데이터 주요 전처리 과정
- 버스 정류장 위치를 구 별로 구분
- 제공받은 데이터의 '정류장ARS' 컬럼 앞 두 자리가 구를 의미했기에 이를 바탕으로 구분
- 결측치 처리
- 구 별 버스 정류장 수 확인
- 데이터 프레임 합치기 - 서울 버스노선별 정류장별 승하차 인원 정보 + 서울시 버스정류장 위치정보
- 승하차 승객 정보 확인
- 최종 데이터 정보 df_seoul_bus_station
: [자치구, 버스정류장 ARS 번호, 노선 번호, 승차총승객수 - 합, 하차총승객수 - 합, 승차총승객수 - 평균, 하차 총승객수 - 평균] - 데이터 시각화
유동인구 데이터 주요 전처리 과정
- 결측치 처리 : 중앙값으로 채움
- 성별, 이동시간별, 요일별 데이터 확인
- 서울 지역 외 데이터 제거
- 지역 코드를 활용하여 지역구 정보 추가
- 심야시간 이동 제외
구별 등록인구 데이터, 구별 업종 등록 데이터 주요 전처리 과정
- 필요한 데이터 컬럼 선정
이후 자치구를 기준으로 전처리한 위의 모든 데이터를 합침
✅ 선정 가설 및 검증 과정에서의 느낀 점
우리 조의 선정 가설
- 평균 승차 승객 수와 노선 수는 연관이 있다.
- 택시운송업 종사자 수와 노선 수는 연관이 있다.
- 평균 이동시간과 노선 수는 연관이 있다.
이변량 분석 결과
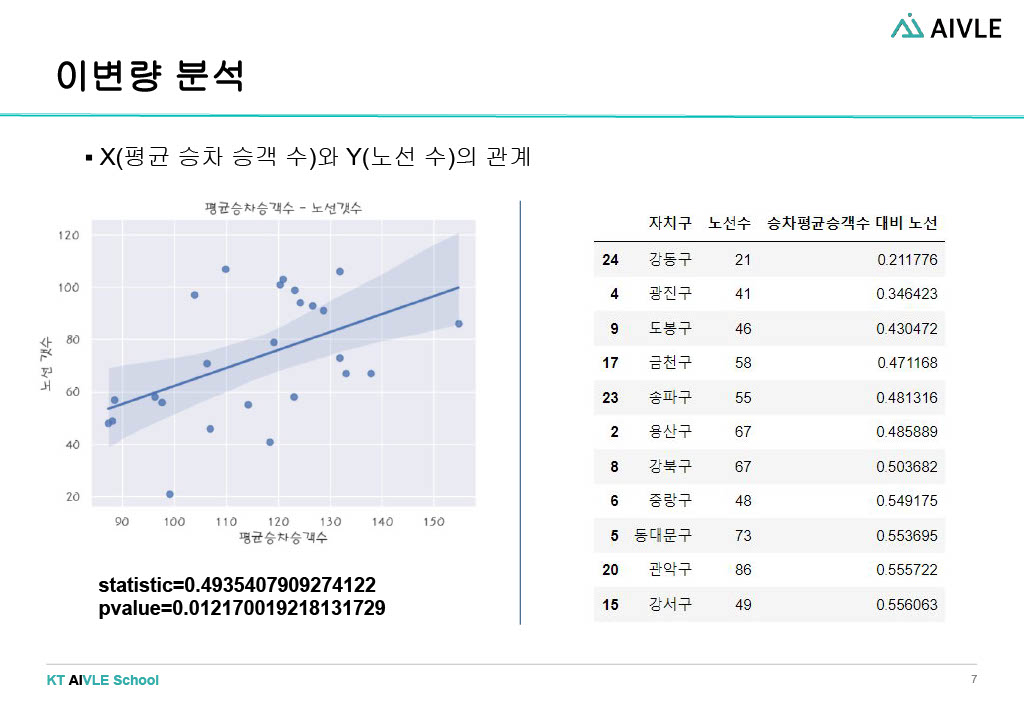
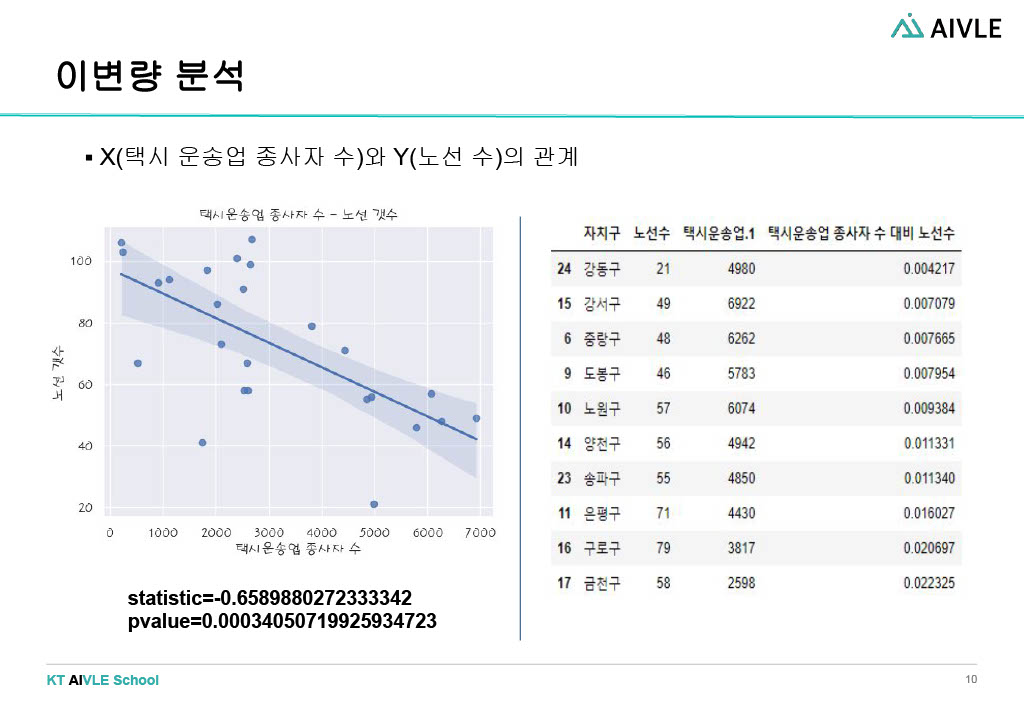
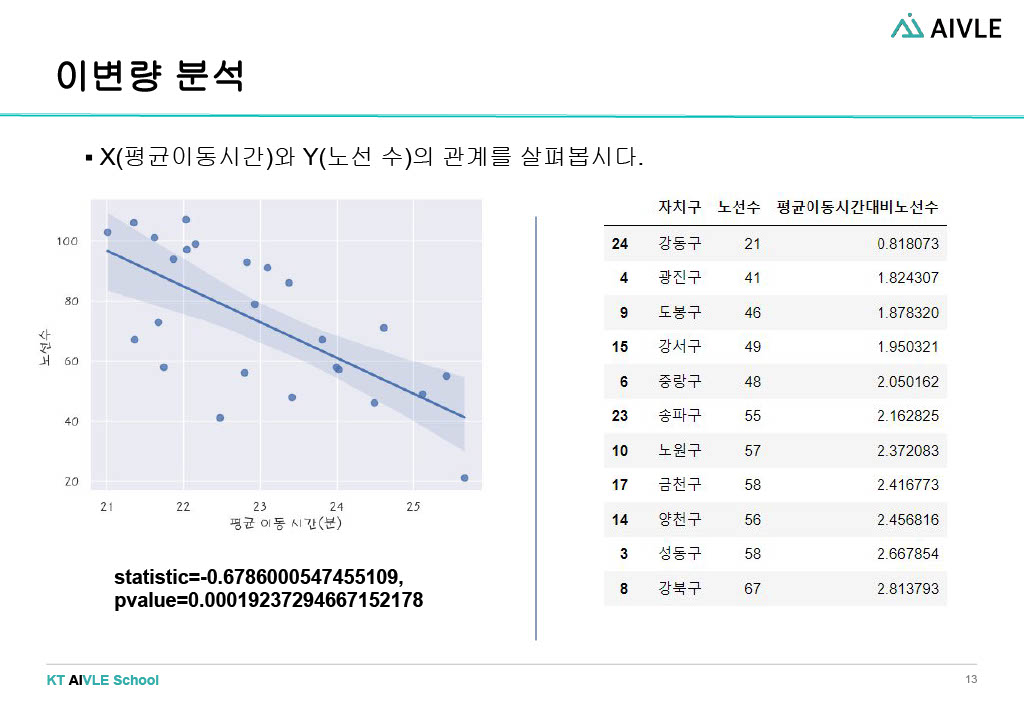
각 데이터(노선 수, 평균 승차 승객 수, 택시 운송업 종사자, 평균 이동시간)에 대한 단변량 분석 후 타겟 데이터와의 이변량 분석을 진행했다. 각 가설을 모두 상관계수와 p-value에서 유의미한 관계를 보였다. 이를 바탕으로 우리 조가 선정한 버스 시설이 추가가 가장 필요한 지역구는 '강동구'! 강동구는 평균 승차승객 수 대비 노선 수가 적었고 이는 승객들이 버스 이용에 어려움을 겪고 있을 거라 추측했다. 동일한 수의 승객들이 선택할 수 있는 노선 수가 자치구 중에서 제일 적었다. 또한 평균 이동 시간 대비 노선 수 역시 자치구 중에서 제일 적었다. 이를 우리는 동일한 이동시간 동안 이용할 수 있는 노선 수가 가장 적은 상황이라 판단했다. 마지막으로 택시 운송업 종사자 수 대비 노선 수는 가장 많았는데, 앞선 가설에서 목적지까지 가는 노선의 수가 적고 시간이 오래 걸리는 편이기 때문에 택시 수요가 많아진 상황이라고 판단했다.
물론 우리는 EDA를 관점으로 접근했고 첫 미니프로젝트인 만큼 상관계수와 p-value 바탕으로 도출한 결과이기에 실제 상황과는 차이가 있을 수 있다. 하지만 도메인 이해 과정부터 여러 가설을 선정하고 각 가설의 결과를 연결하여 버스 시설 추가가 필요한 자치구까지 선정해 봤다는 거에 의미 있던 활동이었다 ㅎㅎ.
특히나 이 날은 다른 조들의 전체 발표 때 엄청 놀랐는데 처음 듣는 여러 툴을 사용하신 조도 있었고, 우리 조는 사용하지 않은 컬럼을 사용해서 결과를 낸 조도 있었다. 능력자 에이블러분들이 많다는 것을 새삼 다시 느꼈다. 😮
Day 11. 미니 프로젝트 1차
- 주제: 서울시 따릉이 수요 분석
- 날씨 데이터와 함께 어떠한 날씨요소가 따릉이 수요와 관련 있는지 분석
- 데이터 분석과 인사이트 도출
첫 번째 미니프로젝트의 마지막 날이었다. 이 날은 조원 분들과 첫 미프이자 나름 KT 교육 프로그램인데 본사 한 번 가봅시다 하는 마음으로 분당 교육장을 예약했다. (그리고 우리는 그 날 이후 분당을 찾지 않고 있다..) 물론!! 분당 교육장은 시설도 널찍하고 구내식당도 있고 아주 좋았지만..... 출퇴근길 지옥철에 시작 전부터 기가 다 빠져버렸다.... 😴😫🥱😪 여튼 그럼에도 널찍한 교육장을 우리 조만 사용하면서 화목하게 미니프로젝트를 마무리할 수 있었다.
✅ 도메인 지식
서울 시민 거의 1/4이 사용 중인 따릉이는 저렴한 대여료로 인해 갈 수록 적자가 생기는 구조라고 한다. 대여량과 대여소는 강서와 영등포 쪽에 많은 상황이다.
✅ 데이터셋
프로젝트에 사용한 데이터는 총 2개(서울시 공공자전거 시간대별 이용정보, 해당 시점의 날씨 자료)이다. 데이터는 서울 열린데이터 광장과 기상자료개방포털에서 확인 가능하다. 데이터는 2021년 4월부터 11월까지의 정보를 담고 있고, 이용정보와 날씨 자료는 마포구로 한정했다. 역시나 EDA를 활용하여 해당 데이터를 살펴보고 가설을 세워 검증하는 과정을 가졌다.
✅ 과정
우리의 프로젝트 목표는 어떠한 날씨요소가 따릉이 수요와 관련 있는지 데이터 분석을 통해 인사이트를 도출하는 것이었다. 지난 이틀과는 달리 하루 만에 데이터 전처리부터 가설 검증, 결론 도출까지 해야 하기에 시간이 촉박하게 느껴지기도 했다. 오전에는 각자 데이터 분석 시간을 가졌고 오후에 함께 회의하며 최종 결론을 도출했다.
<주요 분석 과정>
날씨 데이터 셋 변수 : 날짜, 시간, 온도, 강우 여부, 풍속, 습도, 시정, 오존 수치, 미세먼지 수치, 초미세먼지 수치, 시간에 따른 따릉이 대여 수(target)
- 각 feature를 단변량 분석하며 확인
- 결측치 처리 - 연속형 데이터이기에 bfill을 통해 결측치 처리
- 오존, 미세먼지, 초미세먼지 수치의 경우 기상청에서 제공하는 기준을 바탕으로 범주형으로도 변환 후 확인
- 이변량 분석을 위해 target과 상관계수가 높은 변수 선택
선정 가설 및 검증 과정에서의 느낀 점
우리 조의 선정 가설
- 시간과 따릉이 대여량에는 연관이 있다.
➡ 오후, 저녁 시간 대 평균 따릉이 대여량이 높았다. - 온도 평균과 따릉이 대여량에는 연관이 있다.
➡ 온도가 높은 구간이 일반적으로 낮시간이기에 심야 시간이 아닌 일과시간에 대여량이 높았다. - 미세먼지 농도와 따릉이 대여량에는 연관이 있다.
➡ 예보되는 미세먼지 등급에 따라 따릉이 대여량에 영향을 끼친다. - 강우여부와 따릉이 대여량에는 연관이 있다.
➡ 비가 내린 날에는 따릉이 대여량이 낮다. - 월별 평균온도와 따릉이 대여량에는 연관이 있다.
➡ 평균 온도가 높은 한 여름 보다는 선선한 평균온도를 보이는 봄, 가을에 대여량이 높았다.
회의 시간을 가지고 결정된 가설과 검증 결과이다. 오존, 미세먼지 데이터 외에도 온도와 시간대 역시 범주형으로 나누고 결과를 보니 보다 뚜렷하게 대여량과의 차이를 구분할 수 있었던 것 같다. 마지막 가설의 경우 선선한 평균온도를 보이는 봄, 가을에 대여량이 높은 경향이 나타났는데 5월은 자전거 대여량이 4월에 훨씬 못 미쳐서 의아했다. 이후 당시 뉴스를 살펴보니 이례적인 황사로 인해 기상 상황이 매우 안 좋았음을 알 수 있었다. 이를 통해 수치적인 접근만큼이나 당시 상황에서 놓치고 있는 것은 없는지, 도메인 이해는 충분한지 확인하는 게 중요함을 배웠다.
우리는 해당 가설을 바탕으로 이용량이 많은 출퇴근 시간에 출퇴근 정기패스와 같은 추가적인 할인과 상품 연계로 따릉이 이용률을 높일 수 있는 방안을 고민했고, 추가로 따릉이 이용률이 높은 계절에 유원지, 행사 입장료를 할인해주는 연계 아이디어를 인사이트로 도출했다. 다른 조 발표에서는 제공 받은 데이터로 불쾌지수를 계산해서 상관계수를 구한 조의 발표와 적자 문제 해결이라는 목표에 따라 수요에 따른 가격 조정 아이디어를 낸 조 발표가 인상적이었다.

미니 프로젝트를 이후도 몇 차례 진행하면서 많이 배우고 있다. 수업을 듣는 게 다가 아니구나 하는 깨달음과 함께 팀에 피해를 주지 않으려면 더 열심히 공부해야겠다는 자극도 많이 얻는다. 미니 프로젝트를 하면서 같은 반 에이블러 분들과도 뵐 수 있고 함께 도우면서 성장할 수 있다는 점도 좋은 부분이라고 생각한다. 고럼 어느덧 아득해진 1차 미니 프로젝트 회고는 이쯤 해두고 다음 크롤링 복습으로 돌아오겠다...!
'KT AIVLE school' 카테고리의 다른 글
| [AIVLE/Week4&5] 머신러닝 & 딥러닝 (0) | 2023.06.27 |
|---|---|
| [AIVLE/Week3-2] 데이터 크롤링 (0) | 2023.05.29 |
| [AIVLE/Week2] 데이터와 친해지는 시간 - 파이썬 라이브러리, 데이터 처리, 데이터 분석 및 의미 찾기 (1) | 2023.03.26 |
| [AIVLE/Week1] Hello Aivle World! - IT프로젝트 관리도구(GIT), 파이썬 프로그래밍 (1) | 2023.02.28 |
| [AIVLE/Week0] KT AIVLE school 합격 후 입교식까지✨ (0) | 2023.02.25 |